简单系统设计 —— 索引(五)
本系列,是自己学习Grokking the System Design过程中的笔记。
希望读者在看完全文后,也能留下你们的经验。我万分荣幸能收到你们的消息。
如果能从这里学到点东西,记得请我喝杯☕☕☕~
—— MinRam
一、前言 Overview
当数据量达到一定的规模,数据库的查询性能会明显下降。这时候就是索引的出场。
数据库索引 Index就是为了提高数据库访问数据的速度(即查询的速度 Select/Update/Delete)。它的实现原理在主流数据库中时平衡树(Balance Tree & B+ Tree)。也有部分数据库采用的是哈希桶的结构。
通过记录关键属性的值,在符合条件的查询操作时,就不再需要进行数据库的全表扫描,只需要扫描较少的索引页和数据页。
二、例子 Example
图书馆,一直都是关系数据库的好例子。(😗我绝不是偷懒不去想)
图书馆中收藏书籍的清单,可以看作是数据库的一张表,通常包含了这几个属性:书名,作者,刊号,主题和出版日期。通常在图书馆,有几种经常用到的查询方式:书名检索,作者检索和刊号检索。这样我们就可以通过,书名,作者或者刊号,来轻易查询到一本书或一系列书。
这里的书名,作者和刊号就像图书馆的索引。它们提供一个清晰的数据列表,便于检索。所以索引其实可以理解为一个目录,指向了数据的实际位置。当我们创建索引的时候,我们会存储该列的值,以及指向实际行数据的指针。
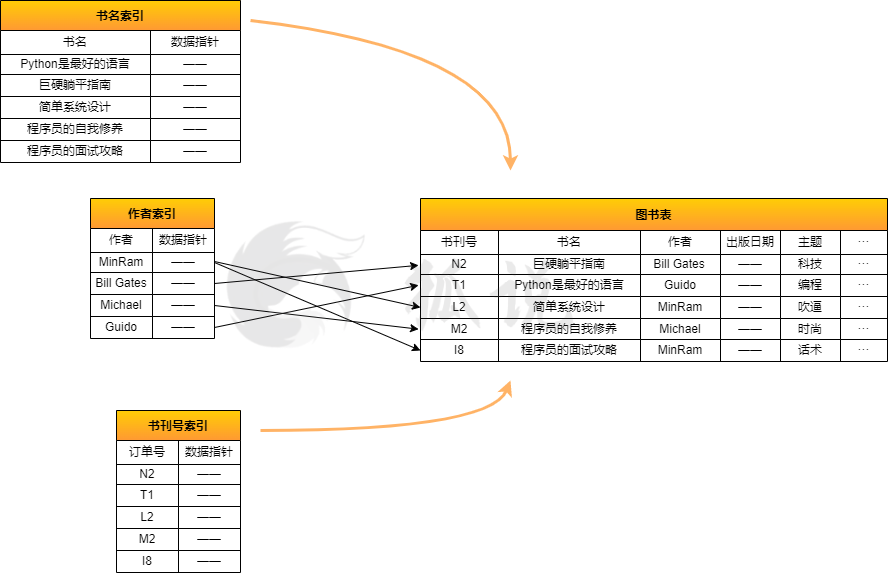
可以发现,索引往往是我们经常检索用到的列属性。 我们把经常操作的数据成为有效负载。
- 对于TB大小级别的数据库,并不是所有数据都是活跃的,例如我们只会在被查水表了,才会去翻看n天前的聊天记录。
因而数据库中有效负载数据,往往是索引的第一选择。
三、代价 Cost
既然索引这么好用,那为啥不暴力把表的所有列全建成索引?
如果把整个表都建成索引,那就跟全表扫描一样的结果了(和二叉树退化成链表同理)。同时,索引的存在会显著加快数据检索,也会减少数据的更新操作(Insert/Update)。具体在于,我们插入一条新数据时,需要更新索引。我们更新到索引关键属性的值时,也同样需要索引。
因此,我们应避免不必要的索引,并即使删除无效的索引。
索引终究只是用于数据的检索动作。如果有个数据库,经常写入数据,但检索的动作占很小的比例,那就没必要再添加索引了。
真没必要脱裤子放屁👻
四、类型 Type (拓展知识)
索引的类型分为一下几种:
4.1 聚合索引
聚合索引 又叫为主键索引,值得就是一张表中的唯一主键。
在现有数据库中,如果建表不指定主键,数据库会拒绝创建表的动作。实际上,一个表如果没有主键,那么他就只能被无序存放,行之间无任何关联,在通过主键检索时,也只能遍历整表。相反的,当我们指定主键后,整个表就变成了索引,从一行行数据,变成了平衡树的结构。(这里不拓展平衡树原理)
1 | SELECT * FROM student WHERE student_id = 88888; |
每个表只有一个聚合索引。聚合索引是通往实际数据的唯一路径。
4.2 非聚合索引
非聚合索引,就是给非主键的属性,加上索引。
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时, DBMS需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。
1 | KEY 'idx_name' ('name') |
- 每创建新的索引,该字段的数据会被单独拷贝出来。即给表添加索引,会导致表的大小增加,占用存储空间。
- 非聚合索引是先通过索引查到主键,再通过主键查到数据。
4.3 联合索引
联合索引, 就是将多个字段联合在一起,构成一个索引。
联合索引,一个重要的用处就是避免回表,其中回表指使用非聚簇索引进行查找数据时,需要根据主键值去聚簇索引中再查找一遍完整的记录。
1 | KEY 'idx_name_sex' ('name', 'sex') |



