简单系统设计 —— 数据分区(四)
本系列,是自己学习Grokking the System Design过程中的笔记。
希望读者在看完全文后,也能留下你们的经验。我万分荣幸能收到你们的消息。
如果能从这里学到点东西,记得请我喝杯☕☕☕~
—— MinRam
一、前言 Overview
分布式系统往往需要处理大量的数据集,如同双十一,电商需要处理上亿级别的订单量,而这些数据如果塞到一台单机数据库上,那他能否处理,以及性能有多差,可想而知。
数据分区 就是将大数据库(DB)分解为许多较小节点的技术。对于一个大规模数据集,通过分割一个DB/表的手段,让多台机器联动处理。从而提高系统的管理能力、性能、可用性以及适当的负载平衡能力。
还有一个关键因素: 当面对DB性能瓶颈时,通过添加更多的机器来水平扩容,往往比更替更强大的服务器垂直扩容来说,更便宜也更可行。
单机数据库的瓶颈:
- 单个表数据量越大,读写锁和插入操作重新建立索引效率越低。
- 单个库数据量太大(一个数据库数据量到1T-2T就是极限)
- 单个数据库服务器压力过大,具体指IO延迟和cpu占用率
- 读写速度遇到瓶颈(并发量几百)
二、分区方式 Partition Method
化整为零的几个主要方式:
2.1 水平分区 Horizontal partig
这种分区形式是对表的行进行分区,通过对某个属性(列)进行分割,得到多个分组,分布在不同的机器上。但整体表的特性仍然存在。这种分区的的关键问题,在于如果分区方式不合理,会导致各分区比重不均匀,导致各个节点的压力不一致。
举个例子:对于淘宝上一年的订单数据,根据每个月份可以分成12个分区。但我们知道11月份的订单数据往往最多。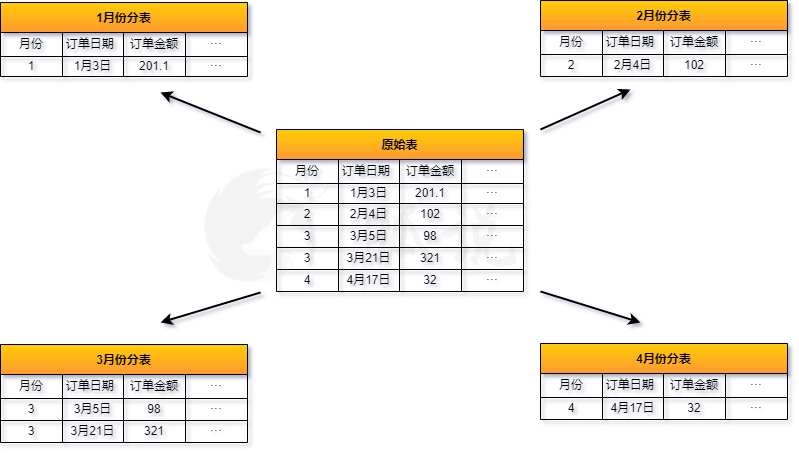
2.2 垂直分区 Vertical
这种分区形式是对表的列进行分区,将不同的表或者是将表的列拆成多个小表,帆布在不同的机器上。这种分区的关键问题,在于随着应用的体量的增长,需要面临进一步的分区。
举个例子: 对于用户表(头像,关注列表,昵称),拆分成个人信息表(头像,昵称),关注表(关注列表)。但随着用户体量的增加,单个服务器仍要面临瓶颈(一个服务器是不可能处理1.4亿用户的元数据查询)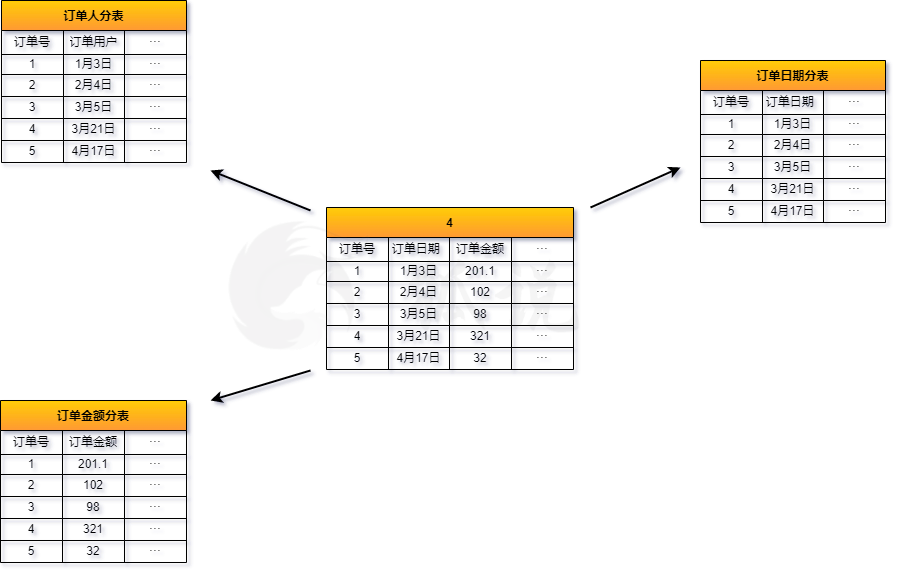
2.3 基于字典的分区 Dictionary Base
以上两种方式都有自己缺陷,因而在实际系统中,经常采用一种松散耦合的方式:抽象数据查找层。即在应用系统到数据元数据间,新增一层机制,单独实现元数据到DB服务器的映射关系。其目的就是能够在不影响应用程序的情况下执行DB池添加节点或者更改分区方案。
- 分区,狭义上指的就是将一个表的数据分成N个区块,在逻辑上仍为一张表,但底层由N个物理块组成
- 分表,就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。
- 分库,分表后数据库中的表会增加,进而需要拆分过于庞大的数据库。
将数据库比作图书馆整个分类,一张表就是一本书。当要在庞大的图书馆找到一本书显然不容易,但若将书籍分成多个类别,就可以通过类别快速找到某个书。
三、划区的依据 Partitioning Criteria
本划区依据,特指水平分区。
3.1 基于键值或哈希的分区 Key or Hash
该方案,就是通过一个哈希Hash函数来映射我们的实体数据的一些属性,生产对应的分区号。例如,我们由N个节点,那么可以通过ID mod N来决定存储的服务器编号。
缺陷:当我们服务器节点增加时,就会更改哈希函数的关系,这需要成功新分配数据和服务停机。但我们可以通过一致性哈希解决问题。详见后续章节。
3.2 列表分区 List
该方案,就是有个列表,决定对应值的记录放在哪个服务器。例如北欧地区的国家为一个分区,亚太地区的国家为一个分区。
3.3 轮询分区 Round-robin
该方案,就是雨露均沾,对于N个分区,编号为I的元数据将被分配到 ‘I mod N’的分区上。
3.4 复杂分区 Composite
数据往往是复杂多样的,小孩子才做选择,实际系统中会结合以上分区方式,提供多层的分区依据。
四、分区的常见问题Common Problems
相比于单点数据库,分区数据库因为实际执行服务器将是个集群,因而会有一些额外的约束条件和额外的执行复杂度:
4.1 连接表 & 反规范化
连接 Join,简单来说就是连接多个表,从而查到所需要的数据。
规范化 Normalization, 就是将表尽可能地拆开,减少数据的冗余。具体可以搜索下数据库的关系范式理论。
在单点服务器中执行连接并没有什么困难,但是一旦数据库由单点转成多个节点后,跨分区的连接通常不可行或性能不高效。解决这个问题的方式就是进行适当冗余的反规范化,让操作只在单表中执行。当然这也带来了新的挑战 - 冗余数据需要保持一致。
4.2 参考完整性 Referential integrity
关系数据库,最常见的两种约束 唯一键约束 和 完整性约束。
参照完整性,简单来说就是,两个数据表是有关联的,父表中的记录必须存在,子表的记录才能存在。显然在分区数据库中强制执行数据完整性约束(比如外键)可能非常困难。
大多数RDBMS不支持跨数据库服务器上的外键约束。
当我们需要这个约束时,就需要应用程序必须在代码中强制执行参照完整性。
在这种情况下,应用程序通常必须运行常规SQL作业来清除悬空引用。
4.3 重新分配 Re-Balance
尽管我们在分区方案设计的很完美,随着系统的数据规模增加,我们都需要面对重新分配分区。
- 按照分区规则,某个分区上的数据超过了承载量。 例如,大量国内用户注册,导致亚太区数据分区存储较大比例的数据
- 某个分区上存在较多的负载。 例如,随着用户体量增加,头像的请求明显增加。
面对这种情况,我们要么构建更多的数据分区,要么重新平衡各分区的数据比例。这就代表我们需要挪动数据前往新的位置,在这过程中要实现不停机是一个很大的挑战。当然,使用字典分区的方式,抽象数据查找层,能有效的实现零停机(Zero-Downtime)的效果,但也暴露了查找层存在故障的可能(单点故障)。
五 其他 Others
分布式数据库是一个很庞大的技术体系,本章只是简单系统设计,重心在于入门。笔者会在后续系统学习数据库后,重新润笔。
对于分布式数据库如果很感兴趣,可以进一步看看 Google Spanner的设计论文。
- Spanner 是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。它是第一个把数据分布在全球范围内的系统,而且支持外部一致性的分布式事务。



