简单系统设计 —— 缓存(三)
本系列,是自己学习Grokking the System Design过程中的笔记。
希望读者在看完全文后,也能留下你们的经验。我万分荣幸能收到你们的消息。
如果能从这里学到点东西,记得请我喝杯☕☕☕~
—— MinRam
一、前言 Overview
负载均衡 帮助我们在节点不断增多的系统上进行水平扩展。而缓存 是帮我们利用现有资源,减少成本较大的逻辑处理。
缓存就是系统的短期记忆。
每一次从后端拿到的数据很有可能再次被使用,那么通过消耗一定的存储空间(内存等),当我们再次需要数据的时候,我们可以直接从存储空间获取,而不是从后端再次申请。这将节省我们很多成本。
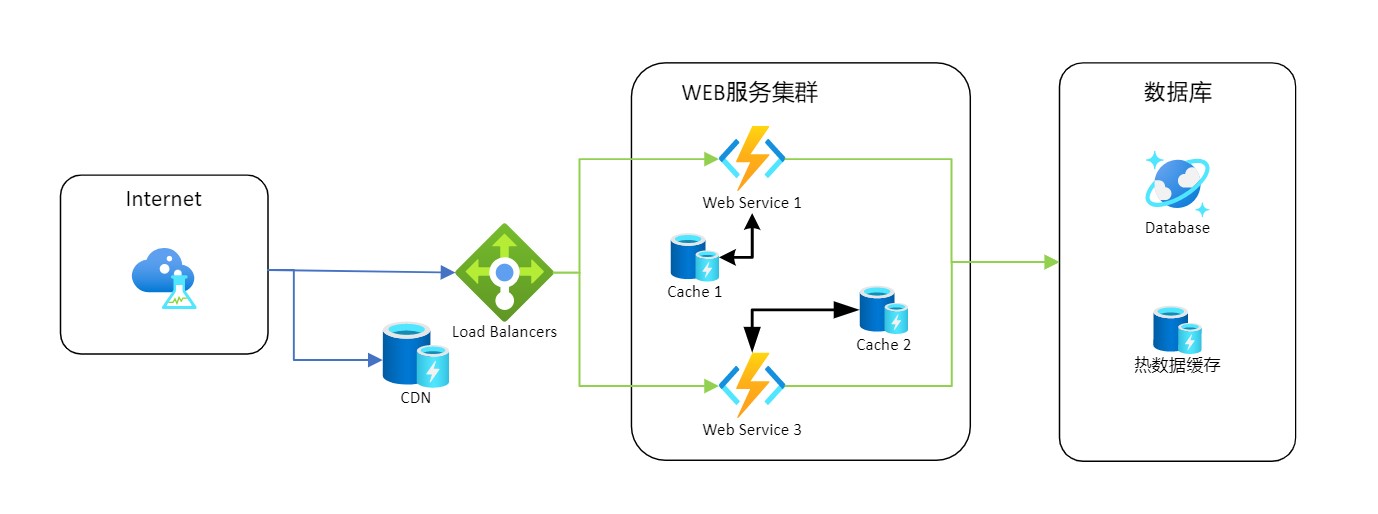
二、在系统中的位置 Position
缓存在很多地方都可以看到,例如硬件上的CPU缓存,操作系统中内存,浏览器上的页面缓存,Web应用上的Redis等
在分布式系统中,缓存往往会使用在较前端的部分,来最大限度的降低下游的请求压力。前面提到,当我们可以直接从缓存拿到数据的时候,就不再需要往下游请求数据。
三、类型 Cache Type
大多数系统主要应用几种类型的缓存:
3.1 应用服务缓存 Appliation Server Cache
在请求层的应用服务器上放置缓存,同时会配置一个本地存储用于暂放请求数据。
对于服务器每次需要发送的请求时,会先检查本地存储中是否已有。如果存在,直接从本地快速获取。若不存在,再发送请求去获取索要的数据。
3.2 数据库缓存 Database Cache
不同于应用服务器缓存所依赖的外部缓存机制(如Redis), 数据库自身也存在缓存。
数据库的数据分为两种:
- 冷数据:通常存储在磁盘上且不经常查询的数据。
- 热数据:频繁查询的数据,会被缓存在内存中。
通过某些级别的配置,可以针对数据库读写模型,在不更改业务代码的情况下就能提供更好的性能。而这就靠DBA或者运维工程师的功底。
笔者在数据库缓存方面并没有太多的经验,不再扩展,待后续补充。
3.3 内容分发网络 CDN
内容分发网络 Content Delivery Network = 更智能的镜像服务器 + 缓存 + 流量导控
CDN 简单来讲就是将内存缓存在离用户更近的地方。采用更多的缓存服务器(CDN边缘节点),布置在用户访问相对集中的地区或网络中。当用户访问网站时,利用全局负载,将访问重定向到用户最近的缓存服务器上。由缓存服务器响应响应的请求。
CDN 将我们的应用服务器从大量的静态资源请求解放出来。对于图片,静态HTML,CSS等的资源,则从CDN节点直接获取。应用服务器将更专注于业务动态处理。
如果我们的站点还不够大,则可以通过像Nginx这样的轻量级HTTP服务器,从单独的子域(static.xxxx.com)提供简单转换。
四、缓存有效性 Invalidation
缓存减少了系统很大部分的多余请求。但是缓存终究只是真实数据(如数据库中的数据)的复制品,存在着和真实数据不一致的风险。
为解决缓存不一致性的问题,提出了缓存失效的概念:
4.1 直写缓存 Write-Through
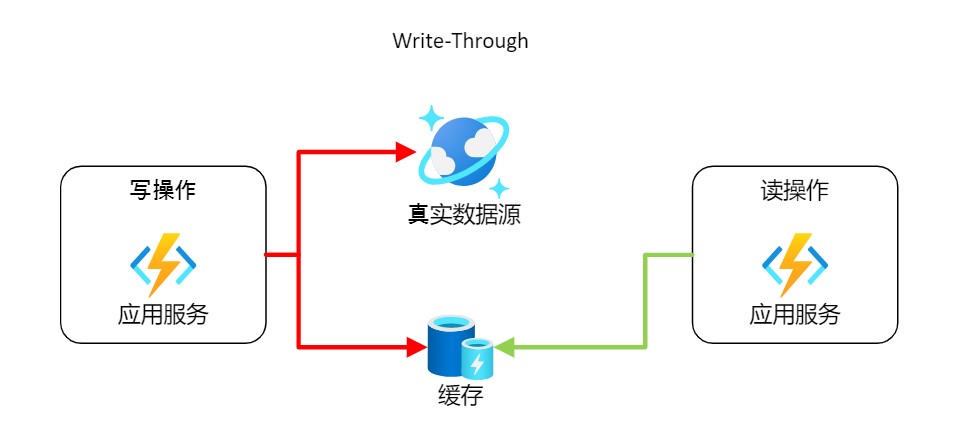
该方案就是在写操作时,同时写入缓存和真实数据源(如数据库)。能保证快速的缓存检索,同时由于写的操作直接写入真实数据源,而具有缓存和存储保持完全的数据一致性。此外由于直接将数据推送给了真实数据源,最小化数据丢失的风险。
缺点: 写操作需要两次操作,因而存在高延迟。适用于频繁写和读的系统。
4.2 绕写缓存 Write-Around
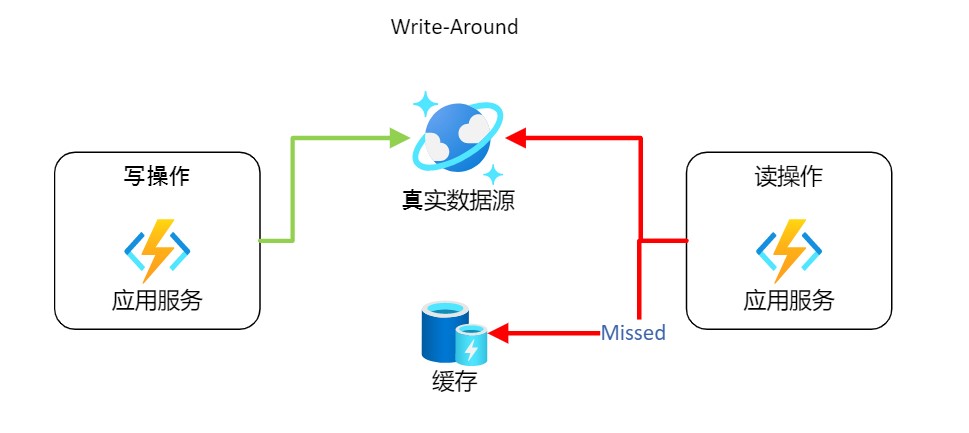
该方案就是在写操作时,绕过缓存直接写入真实数据源。能避免缓存因为数据写入,而频繁更新。
缺点: 读操作会出现缓存丢失,因而需要重新到真实数据源检索,存在高延迟。 适用于不经常读取最近写入数据的系统。
4.3 回写缓存 Write-Back
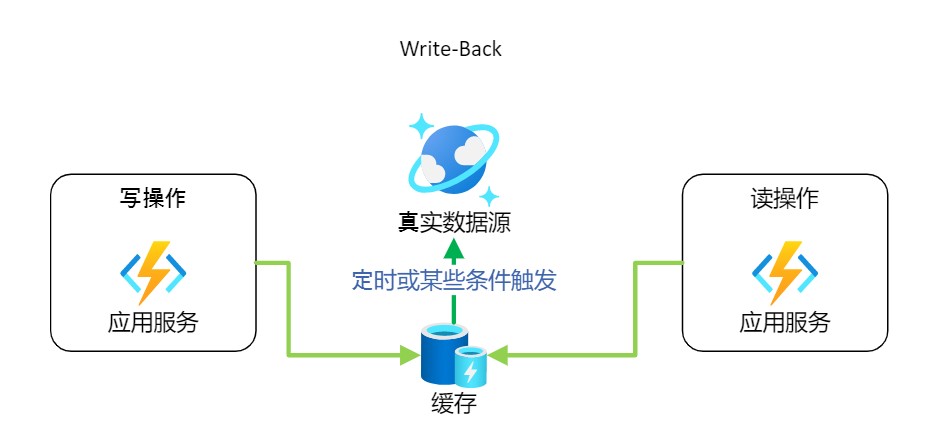
该方案是在写操作时,只写入缓存就结束了。在一定条件(如一定的时间间隔)触发后,更新缓存到真实数据源。这对于写密集型应用程序,这将导致低延迟和高吞吐量
缺点:当节点处于故障时,将导致数据丢失。 适用于写密集行且数据不敏感的系统。
五、缓存淘汰原则 Eviction Policies
细节待更新
常见的几种缓存淘汰原则:
FIFO (First In First Out)
- 先进先出,可以理解为一个队列。当要记录新的缓存,且缓存空间满了的时候,就淘汰缓存中存入时间最早的数据,即队列的头进尾出。
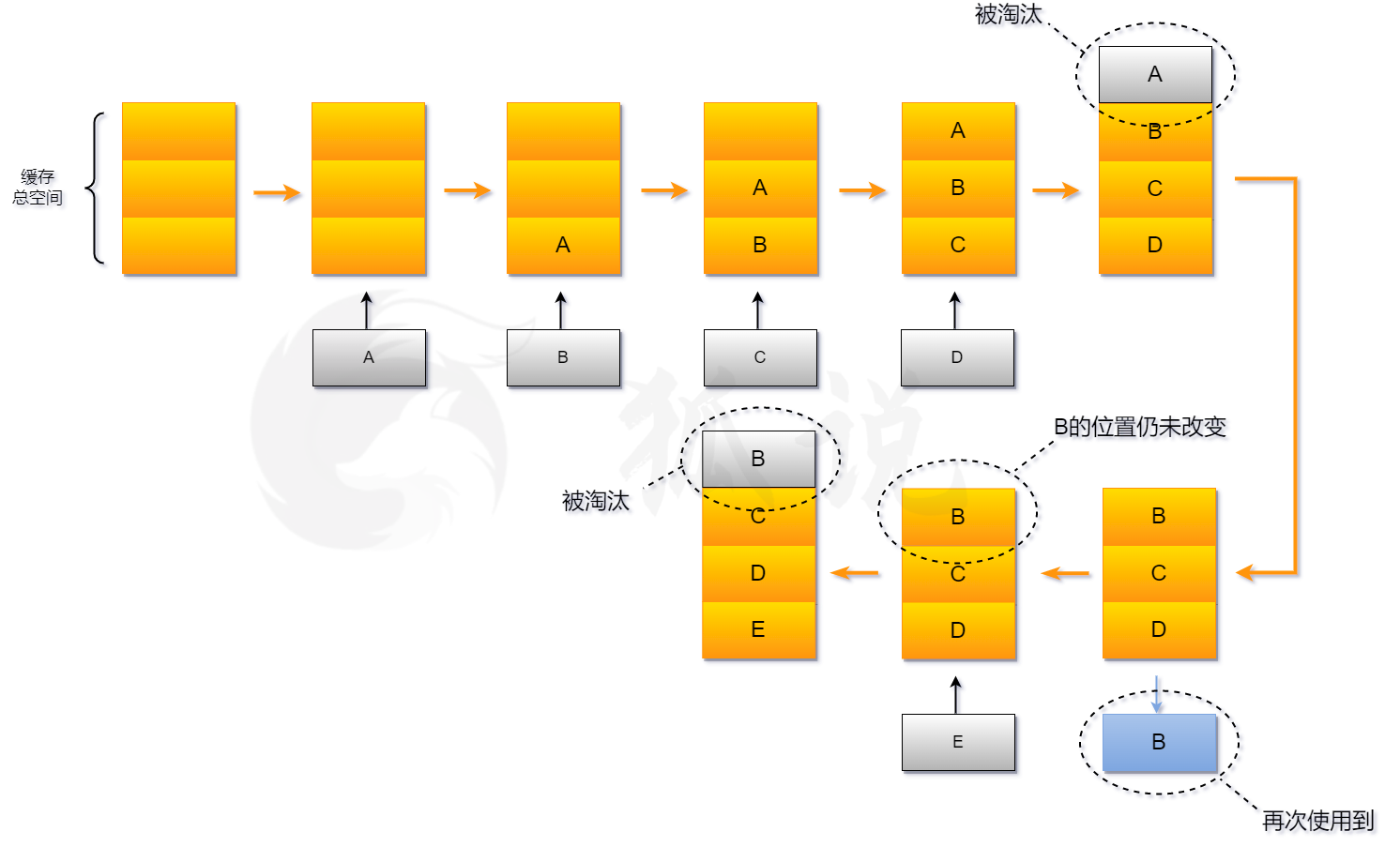
实现原理: Hash表 + 队列
LIFO (Last In First Out)
- 后进先出,可以理解为一个栈。当要记录新的缓存,且缓存空间满了的时候,就淘汰缓存中最新存入的数据,即栈的出栈入栈。
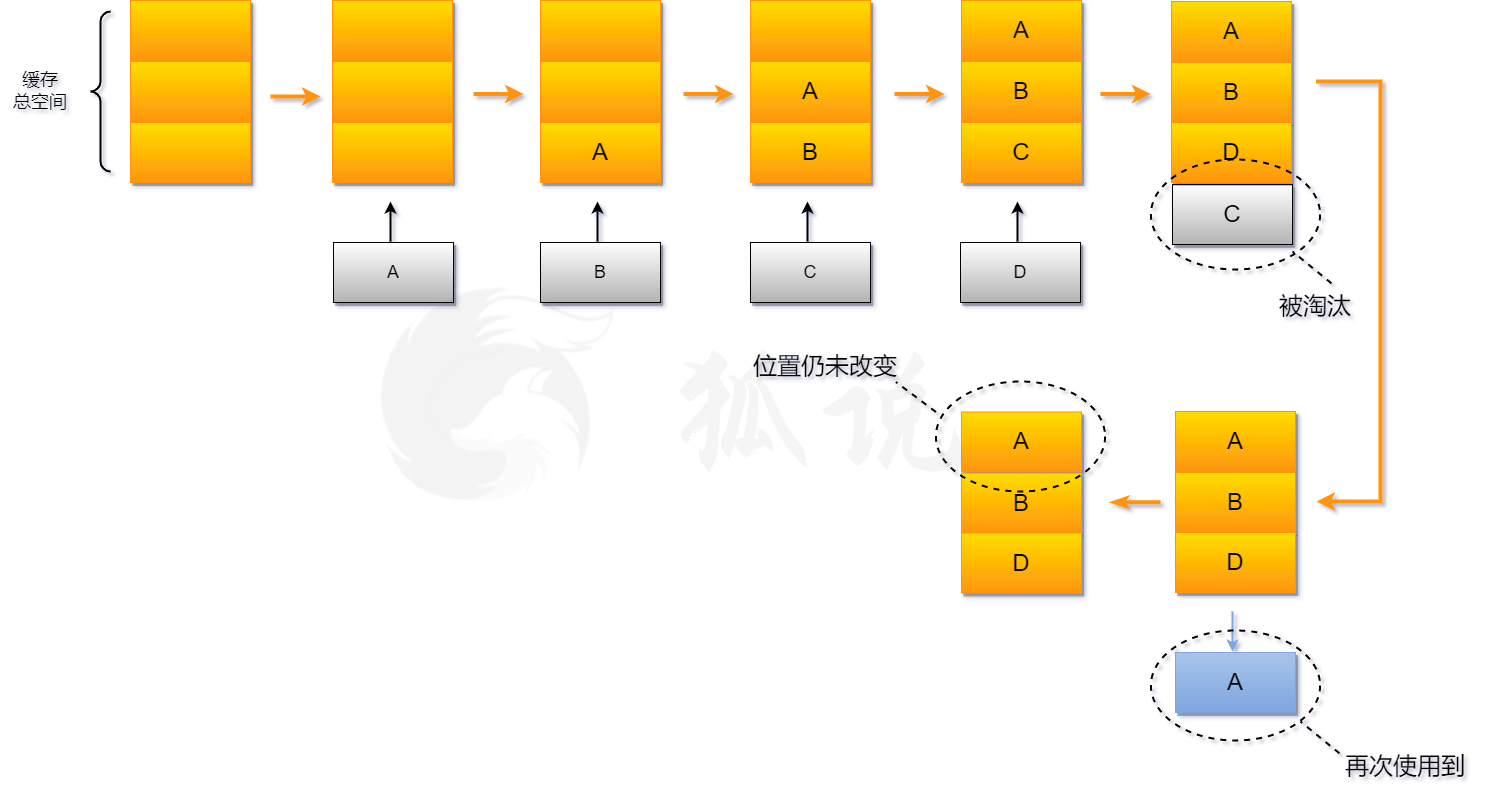
实现原理: Hash表 + 栈
LRU (Least Recently Used)
- 最近最久未使用,可以理解为一个队列,再加上刷新操作。当命中缓存时,就将缓存提出,重新压入队列。当记录新的缓存时,就淘汰最久没有用到的数据,即此时队伍的尾部。
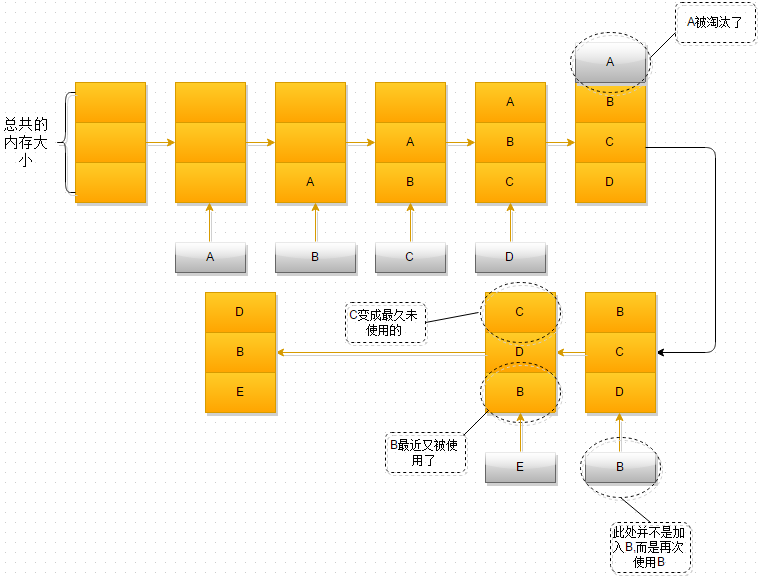
实现原理: Hash表 + 双向链表
LFU (Least Frequently Used)
- 最近最少使用算法,顾名思义,就是淘汰缓存里面用的最少的数据。它根据数据的访问频次来进行淘汰数据,一个数据被访问过,把它的频次+1,发生淘汰的时候,把频次低的淘汰掉。
实现原理:Hash表 + 堆
其他算法
MRU (Most Recently Used)
最近最多使用,同LRU相反,淘汰的时最经常用的缓存。适用于缓存越久没被使用,那下次被使用的概率就越高的场景。RR (Random Replacement)
随机替换,佛系算法,随机替换一个缓存。
六、Redis的实际应用
待Redis系列更新…



