简单系统设计 —— 分布式系统(一)
本系列,是自己学习Grokking the System Design过程中的笔记。
希望读者在看完全文后,也能留下你们的经验。我万分荣幸能收到你们的消息。
如果能从这里学到点东西,记得请我喝杯☕☕☕~
—— MinRam
一、前言 Overview
系统设计(System Design), 即针对系统的应用需求,设计出具有高性能,高拓展性,高可用性等的系统。
每个人学系统设计的目的不一样。笔者的学习目的只有两个:
- 社招面试准备。为通过微软面试的系统设计阶段做准备。
- 脱离底层工作内容(摆脱程序猿的帽子),挺进更具有技术价值的工作领域做准备。
实际工作中绝大多数内容都完全用不到算法,更多是增删查改(CRUD)、对接 API、调整数据格式之类的。更进一步的工作,通常也是和系统设计关系更大。
系统设计面试方面的准备资料,将在《程序员面试攻略》篇补充。
接下来,介绍些现系统中常见的核心模块。
个人对系统设计的理解,也只是冰山一角,并非立山顶,也只是站于山前,从前人留下的斑斑点点揣测大山全貌,其中个人猜想成分偏多,还望各位大师指点迷津。
二、分布式系统 Distubed Systems
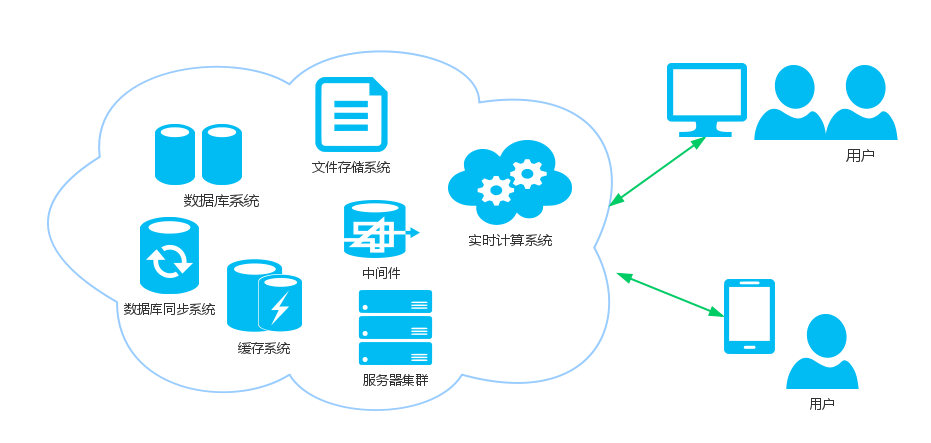
分布式系统,即使用廉价、普通的机器集群,去完成单个机器无法完成的计算和存储任务。其根本目标就是利用更多的机器,处理更多的数据。
比如Google,Microsoft等大型系统,其背后都是由上万台设备组成的数据中心,但对于我们,只感知到他是一个系统。
从特征开始了解:
1.可伸缩性 Scalability
可伸缩性是指当系统的任务(work)增加的时候,通过增加资源来应对任务增长的能力。可扩展性是任何分布式系统必备的特性。
举个例子,跑个算法程序,耗时很久。这时候我们有两种方式可以优化:
- 把原来的电脑换成性能更好的电脑。 ( 垂直扩容 Vertical Scaling)
- 把程序分成两半,分布在两个电脑上分别承担。 (水平扩展 Horizontal Scaling)
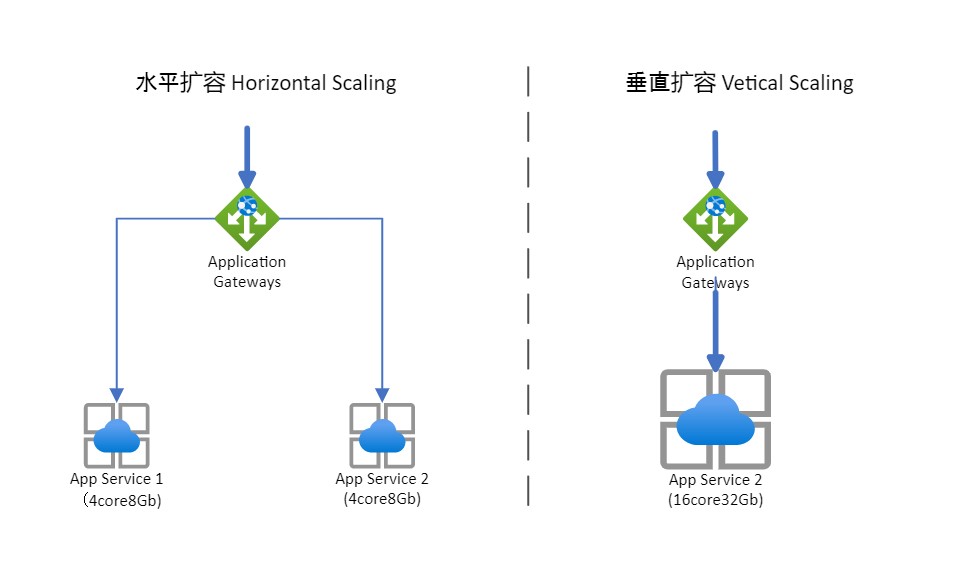
扩展性的目标是使得系统中的节点都在一个较为稳定的负载下工作,这就是负载均衡,当然,在动态增加节点的时候,需要进行任务(可能是计算,可能是数据存储)的迁移,以达到动态均衡。
其中 MongoDB 和 Apache Cassandra 就是典型水平扩容的分布式系统,可以通过增加机器节点,来提升对数据读写的处理能力。而MySQL则是垂直扩容的分布系统,提供了简单的途径用以切换到性能更好或者成本更廉价机器上,但这需要一定的停机时间(DownTime)。
伸缩不仅仅在资源的扩展,也包括在空闲时期对系统的缩容,来节省不必要的资源成本。特别是云时代,算力决定了产品的硬件成本, 淘宝不可能以双十一的处理成本来处理每日的订单。
2.可靠性 Reliability
可靠性关注于系统发生故障(功能故障)的概率。例如当系统中有节点故障时,能被其他健康的节点替代(例如HA, 容灾等),那么可以认为在整体功能上有较高的可靠性。
以淘宝为例,当用户添加一个商品到购物车时候,系统应不丢失这个操作。即使负责处理这个操作的服务器死机,将由另一台服务器快速替代他处理这个操作。
显然冗余是保障系统的一个重要措施。这也同样带来了额外的成本,但对于宝贵的数据丢失,这点不足为道。
3.可用性 Available
可用性关注于系统的所有生命周期里,提供服务的时间比例。
以飞机为例,一个月不间断飞行,那这架飞机的可用性较高。但如果停机维护,那就是不可用。
这里容易把可靠性和可用性的概念混淆:
可用性 被定义为系统的一个属性,它说明系统已准备好,马上就可以使用。换句话说,高度可用的系统在任何给定的时刻都能及时地工作。
可靠性 是指系统可以无故障地持续运行,是一个持续的状态。与可用性相反,可靠性是根据时间段而不是任何时刻来进行定义的。
如果系统在每小时崩溃1ms,那么它的可用性就超过99.9999%,但是它还是高度不可靠。与之类似,如果一个系统从来不崩溃,但是每年要停机两星期,那么它是高度可靠的,但是可用性只有96%。
补充:
- 平均故障间隔时间(MTBF,Mean Time Between Failure),是指相邻两次故障之间的平均工作>时间,是衡量一个产品的可靠性指标。
- 平均修复时间(MTTR,Mean Time To Repair),是描述产品由故障状态转为工作状态时修理时间的平均值。在工程学中,MTTR是衡量产品维修性的值.
在维护合约里很常见,并以之作为服务收费的准则。
$$ Availability = \frac{MTBF}{MTBF + MTTR} $$
4.高吞吐 Effective
一个系统的高吞吐,指的是处理业务请求的效率,体现在两个方面: 响应时间 & 吞吐量
响应时间,系统响应一个请求或输入需要花费的时间。 响应时间直接影响到用户体验,对于时延敏感的业务非常重要。
吞吐量,系统在一定时间内可以处理的任务数。这个指标可以非常直接地体现一个系统的性能,就好比在客户非常多的情况下,要评判一个银行柜台职员的办事效率,你可以统计一下他在 1 个小时内接待了多少客户。常见的吞吐量指标有 QPS(Queries Per Second)、TPS(Transactions Per Second)和 BPS(Bits Per Second)。
一个大型系统的操作业务是复杂繁琐的。以上两个指标只是粗略地估计系统的效率。
除此之外,还有网络拓扑结构,网络负载和变化,涉及硬件还要考虑IO的读写等,要对一个大型系统建立性能模型,这依赖于对各方面性能指标的采集。
5.服务性 & 可管理性 Serviceability or Manageability
该点考虑的是系统运行中,必经的修理和维护周期。
设计分布式系统时的一个重要考虑事项是操作和维护的容易程度。这决定了系统能保持可用时间的长短。
- 可管理,指在系统进行维护或者修复的简易程度和耗时长短。(如果系统不容易修复,那可以理解为系统将较长时间处于不可用状态)
考虑这点特性,需要关注与系统发生问题时:
- 能轻易找到问题根因,
- 快速提出问题修复方案
- 更新版本或者修复问题所需要的成本(停机?人力?物力?)
- 系统的操作所需要的技能程度
可管理性的考虑需要涉及到系统的整个生命周期(发布,更新等)。
题外话,服务性&可管理性,在现在的大型系统中更侧重于运维的能力和成本。
因此就有了Google提出的SRE团队的出现,专门针对整个系统的管理能力开发一系列监听和处理的模块。用来预测,监听和无人工干预的修复各种问题风险。
在当下也有部分公司开始启动了更加创新的AIOps计划,结合智能领域,实现系统的智能管理。
综上的特征,最后根据自己产品特性需求,如搭积木般选择各式各样的组件,形成了如下的分布式系统(图中为典型组件,并非最佳组件选择):
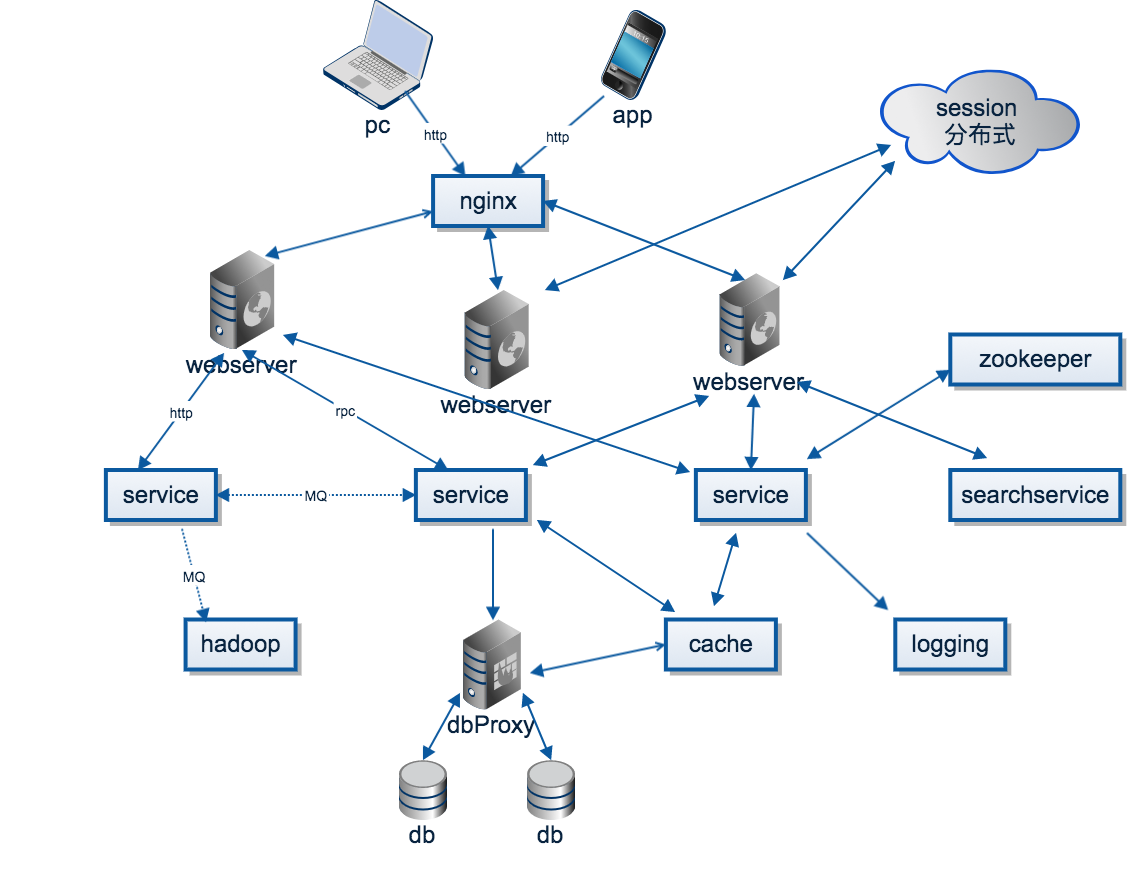
简单系统设计 —— 分布式系统(一)
https://minram.github.io/xi-tong-she-ji/systemdesign-01-distubed-system/



